AI Scaling: Expanding the Role of Artificial Intelligence in Your Organization
)
Pilot projects show that an AI concept can succeed in a controlled setting, but they reveal little about whether it will continue to work when exposed to the data, systems, and cost pressures of everyday business. Moving from a small success to a dependable, affordable service is the essence of scaling.
Most organizations will soon run not just one AI system but many, each embedded in different parts of the business, and each generating its own data. Analysts already see this transition underway. Gartner expects that by 2030, the majority of enterprise software will include multimodal AI that can handle text, images, speech, and structured data together. That expansion brings powerful new capabilities but also a need for structure and discipline.
The most dependable way to scale AI is through a shared platform. Identify what your workloads have in common (how data flows, how security is handled, and how deployment occurs, for example) and then design those elements once for everyone to use. The platform becomes the standard path from idea to production. It shortens delivery time, makes cost and risk measurable, and prevents every team from reinventing the same processes. As demand rises, you expand the platform’s capacity instead of rebuilding each workload separately.
Communities are already defining open standards for these environments. llm-d, for example, coordinates distributed inference on Kubernetes so that large models can be served efficiently across clusters. This movement reflects the same logic Mirantis applies in its own work: open software on Kubernetes provides the most stable and portable foundation for running AI at scale. The reasoning behind that view appears in Randy Bias’ recent blog, Scaling AI for Everyone.
What AI Scaling Means
AI scaling combines two forms of growth: organizational and technical. Organizational scaling deals with how AI systems spread through the enterprise — how people, processes, and budgets adjust to support them. Technical scaling deals with how performance improves or fails as data, parameters, and compute grow. The two advance together. Business expansion drives technical demand, and technical limits shape business outcomes.
In practice, scaling means turning prototypes into durable services. Early efforts rely on small datasets and a handful of models. Mature organizations build consistent data pipelines, standardize packaging and release processes, and share infrastructure for model training and AI inference. Governance and monitoring evolve alongside these systems so that reliability, cost, and policy compliance can be measured in business terms. A company that reaches this stage no longer treats AI as a series of experiments. It treats it as a managed capability.
The Benefits of Scaling Well
Faster delivery through standard paths
Teams work faster when they reuse the same components and follow consistent release steps. Shared environments remove setup delays, and common checks reduce integration friction. As engineering patterns stabilize, attention shifts from plumbing to solving actual business problems. Lessons learned in one use case apply immediately to others, spreading good practices across the organization.
Lower unit cost through shared capacity
Pooling GPU and storage resources raises utilization and lowers idle time. Standardized packaging eliminates fragmentation that wastes compute. Budgets and quotas stop uncontrolled growth. When teams can see and compare cost per experiment or cost per thousand inferences, they can optimize spending and plan with confidence.
Stable services through controlled rollout
Gradual release and reliable telemetry limit the damage from unexpected model behavior. Autoscaling and queueing handle traffic spikes automatically. Critical workloads stay available while noncritical tasks wait their turn. Fewer emergencies mean more predictable service and lower operational stress.
Clear governance and compliance
One unified policy for privacy, retention, and human review avoids confusion. Versioned data, models, and prompts create traceable histories. Testing gates and approval workflows ensure that standards are met before deployment. With ownership and reporting built into the process, oversight becomes part of normal operations rather than an external audit exercise.
Better decisions through consistent measurement
When teams connect model quality and cost to business metrics — conversion rate, resolution time, or throughput — they can make rational trade-offs. Common evaluation methods reduce noise and make comparisons meaningful. Sharing evaluation sets, code, and reports allows improvements in one group to lift performance across the board.
Understanding the Scaling Laws of AI
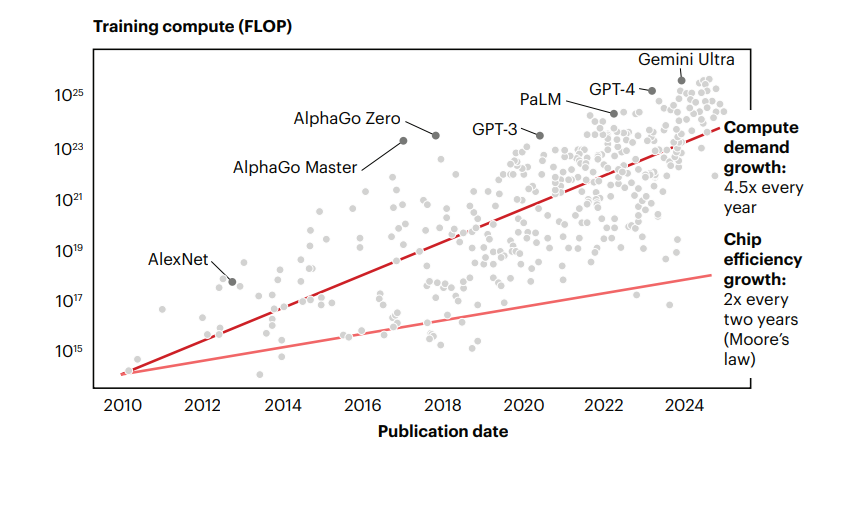
Technical scaling follows patterns known as scaling laws, which describe how accuracy and efficiency change as models grow. NVIDIA’s overview explains why improvements depend jointly on model size, data quantity, and compute budget. Our World in Data documents the rapid rise of all three since deep learning took off a decade ago. Knowing how these factors interact helps leaders decide where investment still yields returns and where diminishing gains begin.
| Variable | What changes as it grows | Why it matters |
| Model size | Larger models capture richer patterns and often lower error on test data | Benefits taper as costs rise and latency increases |
| Dataset size | More diverse data improves generalization and reduces overfitting | High-quality data can often outperform model enlargement |
| Compute budget | Longer runs and larger batches improve convergence | Compute cost drives timelines and financial limits |
Post-training and test-time scaling
Improvement does not stop after training. Techniques such as distillation and preference tuning can increase efficiency or safety without starting from scratch. Test-time scaling allocates more compute during inference, sometimes boosting accuracy or robustness. The trade-offs are described in OpenAI’s summary and in the arXiv paper that supports it.
Suggested image: a chart from Our World in Data showing the exponential growth of parameters and compute over time.
Tools That Make Scaling Possible
MLOps platforms tie together data versioning, experiment tracking, model registries, and release automation so that teams build on one another’s work instead of duplicating it.
Training and inference orchestration distributes jobs across shared GPU pools and places workloads intelligently to maximize throughput.
API gateways and inference routers control endpoints, apply quotas, and route traffic among model versions to balance cost and latency.
Observability and evaluation provide real-time insight into drift, bias, and performance. Shared dashboards give both engineers and managers a common view of status.
Data pipelines and governance enforce lineage and access control, ensuring that data used for training and inference meets policy requirements.
Developer self-service gives teams predefined templates and resource quotas so they can deploy quickly without extra help from infrastructure staff.
When these layers use the same identity, policy, and telemetry systems, models move from lab to production without breaking traceability or security.
Why Physical and Financial Limits Matter
AI scaling depends on electricity, capital, and supply chains that are already strained. Ignoring those realities leads to plans that collapse on contact with the physical world.
The Bain & Company report estimates that U.S. data centers could need 100 gigawatts of additional power by 2030, while compute demand is rising faster than chip efficiency. Bain also projects half a trillion dollars a year in data center investment to keep up. Such spending demands multi-year financing and careful prioritization. High-bandwidth memory and advanced packaging remain bottlenecks, keeping costs high and deliveries slow. The Stanford AI Index 2025 notes that inference costs now dominate training costs for most enterprises, making runtime efficiency a strategic concern rather than a technical detail.
How to Scale AI Across the Organization
1) Build a shared platform
Create a platform that handles training and AI inference with consistent identity, networking, and storage. Choose portable architectures that can span data centers and clouds. The Mirantis guide AI on Kubernetes: Scaling Smarter, Running Faster with k0rdent outlines how to do this in practice. Agree early on release steps, metrics, and budgets so every team works within the same framework.
2) Design for cost and performance at inference time
Most of the long-term spending will occur during inference. Use pooling and right-sizing to keep hardware fully used but not overloaded. Apply caching and routing to reuse results where possible. Consider test-time scaling only when the quality gain offsets the cost. NVIDIA’s description of AI factories offers a way to think about capacity planning and efficiency at production scale.
3) Industrialize evaluation and safety
Treat model evaluation and safety as part of engineering, not compliance. Maintain shared test sets and automatic checks in the release process. Include human review where the business impact is high. Draw on current research, such as the OpenAI and arXiv papers, to keep guardrails current as models and use cases evolve.
4) Change how people work
Scaling succeeds when people adopt new habits, not just new tools. Update incentives so teams actually use the shared platform. Replace ad-hoc validation with continuous testing and targeted human oversight. Publish reliability and cost targets, and reward teams that meet them. Recognize those who improve common components as much as those who launch new projects.
5) Plan capacity and sustainability together
Power, cooling, and siting are now strategic variables. Coordinate with facilities and finance on long-term scenarios for growth. For regulated data or sovereignty requirements, consider a sovereign AI cloud. Apply utilization targets and time-of-day scheduling to keep hardware productive. When sustainability and cost goals align, efficiency improves naturally.
Scaling AI Responsibly
Make model behavior visible
Publish dataset and model cards that describe scope, inputs, and limits. Log key decisions and open evaluation results to product and risk leaders. Visibility encourages accountability and supports faster improvement.
Reduce and monitor bias
Use bias tests suited to each use case. Keep humans in the loop for high-stakes decisions. Track results by demographic or regional segment and adjust data as needed. Privacy-preserving techniques help gather representative samples without violating compliance.
Provide explanation where it matters
Adopt interpretability tools that match the model family and the needs of stakeholders who must approve or contest results. Explainability is a communication task as much as a technical one.
Source data responsibly
Record where data comes from and under what terms it can be used. Validate quality and representativeness often. Update retention rules so they are easy to follow. A clear, auditable request and approval process prevents accidental misuse.
Treat governance as a working system
Policy should live inside code and pipelines, not in isolated documents. Automated checks enforce rules and raise alerts when exceptions occur. Reports should link governance outcomes to business measures such as cost, reliability, and risk so executives see the value of doing it right.
Scalable AI with Mirantis
Mirantis helps enterprises scale AI with open technology, secure infrastructure, and clear guardrails for both builders and business owners. You can standardize on the AI on Kubernetes approach, run secure multi-tenant clusters, and serve models using the portable AI inferencing platform. Sovereignty goals can be met with the sovereign AI cloud, giving control over where data lives and how it is governed. For background on runtime economics and operating practices, consult the Mirantis guide to AI inference.
Platform benefits:
Composable building blocks expressed as declarative templates, that integrate with existing systems and shorten time to value
Portable clusters that span data centers and clouds, including edge locations
High GPU utilization through shared scheduling that keeps cost per request predictable
Built-in observability, evaluation, and governance
Freedom to use preferred training and inference frameworks
Book a demo to see how Mirantis supports efficient, responsible AI scaling across the enterprise.
)
)
)
)

)
)