Model Deployment and Orchestration: The Definitive Guide
)
Contents
- What Is Model Deployment?
- Why Is Model Deployment Important?
- Types of Model Deployment
- When Is a Model Ready for Deployment?
- Development vs. Deployment
- Machine Learning Deployment Methods
- How to Deploy an ML Model to Production?
- ML Model Deployment Architecture
- Model Deployment Best Practices
- What Are the Top Model Deployment Challenges?
- Model Deployment Examples
- Machine Learning Model Deployment Tools
- Simplify Machine Learning Model Deployment with Mirantis
Deploying machine learning (ML) models is a critical part of the machine learning lifecycle, yet it is often overlooked and undervalued. A lot of emphasis is placed on building accurate models, but machine learning can only create real value when these models are actually deployed; this is why it’s essential to understand how to deploy models effectively.
This guide explores what model deployment is, how it works, and best practices for ensuring your enterprise maximizes its ML investments.
Key highlights:
Effective model deployment makes it possible for models to deliver predictions and have real-world impact
Deployment methods (such as REST APIs, containerization, and serverless solutions) offer flexibility based on latency, scalability, and infrastructure needs.
Continuous monitoring, version control, and feedback loops help maintain model accuracy, reliability, and long-term performance.
Mirantis simplifies model deployment and orchestration with k0rdent AI, providing Kubernetes-native scaling, observability, and streamlined automation.
What Is Model Deployment?
Model deployment is the process of taking a trained machine learning model and making it output results to real users. In other words, it’s the bridge between developing a model and delivering real-world value.
AI model deployment specifically refers to all the steps involved in packaging, distributing, managing, operating, and monitoring an ML model in production. Thinking through this strategy is important because without a plan, even the best models will remain unused.
By deploying machine learning models, organizations turn prototypes into practical applications that can drive business decision-making and automate processes.
Why Is Model Deployment Important?
Model deployment is a critical step in transforming machine learning projects from isolated experiments into systems with real-world impact. Without deployment, even the most sophisticated models have no way to automate processes, enhance user experiences, or inform strategic decisions. For example, deployed models can recommend products on an online shopping platform, flag potentially fraudulent transactions on a credit card, or analyze medical scans for early disease detection.
One of the primary reasons why model deployment is important is its ability to generate business value. Once a model is live in production, it can:
Serve predictions that support applications
Create operational efficiencies
Open up entirely new revenue streams
Deployment also enables scalability. A deployed model is accessible to many users, often in real time, dramatically increasing its reach and usefulness.
The creation of a feedback loop is also valuable. Models in production can gather real-world data about model performance, which helps with ongoing improvements. This process maintains model relevance and accuracy in changing environments. Finally, model deployment is useful for operationalization. If data science outputs are not integrated into business workflows, they remain disconnected from the systems they are supposed to improve.
Ultimately, knowing how to effectively deploy AI models is necessary for machine learning models to live up to their full potential.
Types of Model Deployment
There are numerous ways to deploy an ML model depending on the use case, infrastructure, and business needs. Understanding model deployment tools is necessary to choose the most efficient strategy, as each of these approaches involves trade-offs in latency, scalability, and complexity.
Common types of model deployment include:
| Deployment Type | Summary | Latency | Scalability | Complexity |
| Batch deployment | Models run on a schedule (e.g., nightly) to process large amounts of data. Predictions are stored for later use. | High (minutes to hours) | High (handles large data volumes) | Low to moderate |
| Online (real-time) deployment | Models serve predictions via APIs in real time as requests arrive. | Low (milliseconds to seconds) | High (requires load balancing and auto-scaling) | Moderate to high |
| Edge deployment | Models are deployed on edge devices (e.g., mobile phones, IoT devices) to enable low-latency predictions offline. | Very low (local inference) | Limited to device capacity | High (resource-constrained environment) |
| Embedded deployment | Models are embedded directly in software applications or firmware. | Very low (local, no API calls) | Limited to app distribution | High (tight integration, versioning challenges) |
| Inference as a Service | Models are hosted on cloud services that provide scalable, on-demand inference endpoints. | Low to moderate (depends on service) | Very high (cloud-native scalability) | Low to moderate (abstracted infrastructure) |
When Is a Model Ready for Deployment?
It is important to accurately gauge when a model is ready for deployment. Premature deployment can erode user trust, but endless tuning is inefficient and delays business value.
A machine learning models should only be deployed once it:
Meets predefined performance goals on validation and test data, and generalizes well beyond the training set
Demonstrates robustness and stability across different data variations, which helps safeguard against unexpected behavior in production
Is easily comprehensible for relevant stakeholders to foster trust and accountability
Beyond performance and interpretability, a model must be checked for bias, fairness, and security vulnerabilities. It is also important to track the model’s performance after deployment; it is a good idea to set up monitoring for issues like data drift, concept drift, latency, and system errors.
Finally, the model should be fully integrated with Continuous Integration/Continuous Deployment (CI/CD) pipelines to support automated deployment and rollback. This will make sure that updates are delivered reliably and securely over time.
Development vs. Deployment
Development and development involve completely different goals and processes.
Development is mainly centered around building the model, which includes:
Selecting features
Training algorithms
Tuning hyperparameters,
Evaluating performance on offline data
The focus here is on optimizing the model. Deployment, on the other hand, is about making the model operational. The goal shifts from building the algorithm to running it reliably in the real world. Deployment involves:
Packaging the model
Integrating it into existing systems
Ensuring it can handle live traffic with appropriate latency and scalability
Deployment also requires adding monitoring, versioning, and rollback mechanisms to make sure the model behaves as expected.
In short, development focuses on creating the model while deployment focuses on getting the model up and running.
| Aspects | Development | Deployment |
| Focus | Model training and evaluation | Model packaging and serving |
| Primary Activities | Experimentation with data and algorithms | Integration with production systems |
| Key Metrics | Accuracy, F1, etc. | Latency, uptime, throughput |
| Location | Often offline or local | Always-on, monitored, scalable |
Many teams underestimate the effort required for scaling, monitoring, and versioning in production; it’s a fundamentally different challenge from model development.
Machine Learning Deployment Methods
There are many different ways to deploy machine learning models. Here are some of the common methods used today:
REST API Deployment: Make the model available through a REST API using tools like Flask, FastAPI, or frameworks like TensorFlow Serving or TorchServe.
Containerization: Package the model and its dependencies into a Docker container, enabling portability and reproducibility.
Kubernetes-Based Deployment: Use Kubernetes for Kubernetes management of containerized models, allowing for auto-scaling, load balancing, and high availability.
Serverless Deployment: Deploy as serverless functions (e.g., AWS Lambda, Google Cloud Functions) for event-driven or lightweight workloads.
Cloud ML services: Use services like AWS SageMaker, Google Vertex AI, or Azure ML to deploy and manage models with built-in MLOps capabilities.
The best machine learning deployment method depends on the application’s latency requirements, scalability goals, and existing infrastructure. Alignment with technical needs and team capabilities is a key step for models to deliver maximum value in production.
How to Deploy an ML Model to Production?
Deploying an ML model involves preparing itfor real-world use, integrating it into production systems, and checking that it runs reliably. Here’s a high-level process:
1. Package the model
The first step is to package the trained model into a format that can easily be saved and transferred. Common formats include Pickle (for Python-based models), ONNX (Open Neural Network Exchange, for cross-framework compatibility), and SavedModel (for TensorFlow). Packaging makes it possible for the model to be consistently loaded into the production environment and used to make predictions.
2. Prepare the Serving Infrastructure
Next, you need to design how the model will be served in production. Options include exposing the model through a REST API for real-time predictions, setting up a batch pipeline for processing large datasets on a schedule, or deploying the model to an edge device for offline, low-latency inference. The choice of serving infrastructure depends on your use case, latency requirements, and available resources.
3. Containerize
For portability and reproducibility, the model and its serving application are often containerized. Containers allow you to package the model and its dependencies, runtime environment, and API server into a single deployable unit. This makes it easier to run the model consistently across different environments (development, staging, production) and simplifies scalable deployments.
As ML deployments scale, container orchestration becomes increasingly important for managing distributed services, automating rollouts, maintaining security, and optimizing resources; tools like Kubernetes provide the control and flexibility needed to handle these demands.
Mirantis Kubernetes Engine (MKE) provides a CNCF-certified, enterprise-grade Kubernetes distribution that simplifies container orchestration across any environment, along with built-in security features, making it ideal for deploying ML workloads at scale.
4. Automate Deployment
Next, it’s important to automate the deployment process using CI/CD pipelines. Automated pipelines make it easy to reliably test, validate, and deploy new versions of the model. Automation also supports version control and rollback, speeding up iteration cycles and reducing human error.
5. Monitor the Model
Ongoing monitoring is crucial after deployment. Monitoring can detect issues early and helps teams maintain model accuracy and reliability over time. Key metrics to focus on include latency, error rates, and signs of data drift.
6. Enable Feedback Loops
Finally, an effective deployment should incorporate feedback loops. This means capturing production data and outcomes, and feeding that information back into the model development process.
Feedback loops allow data scientists to retrain models on fresh data, correct for drift, and continuously improve model performance. They also support experimentation, such as A/B testing new model versions against existing ones.
ML Model Deployment Architecture
Successful ML deployment relies on thoughtfully designed architecture that combines data sources, model serving, infrastructure, and monitoring into one cohesive system. An ML model deployment architecture has many parts that need to reliably work together.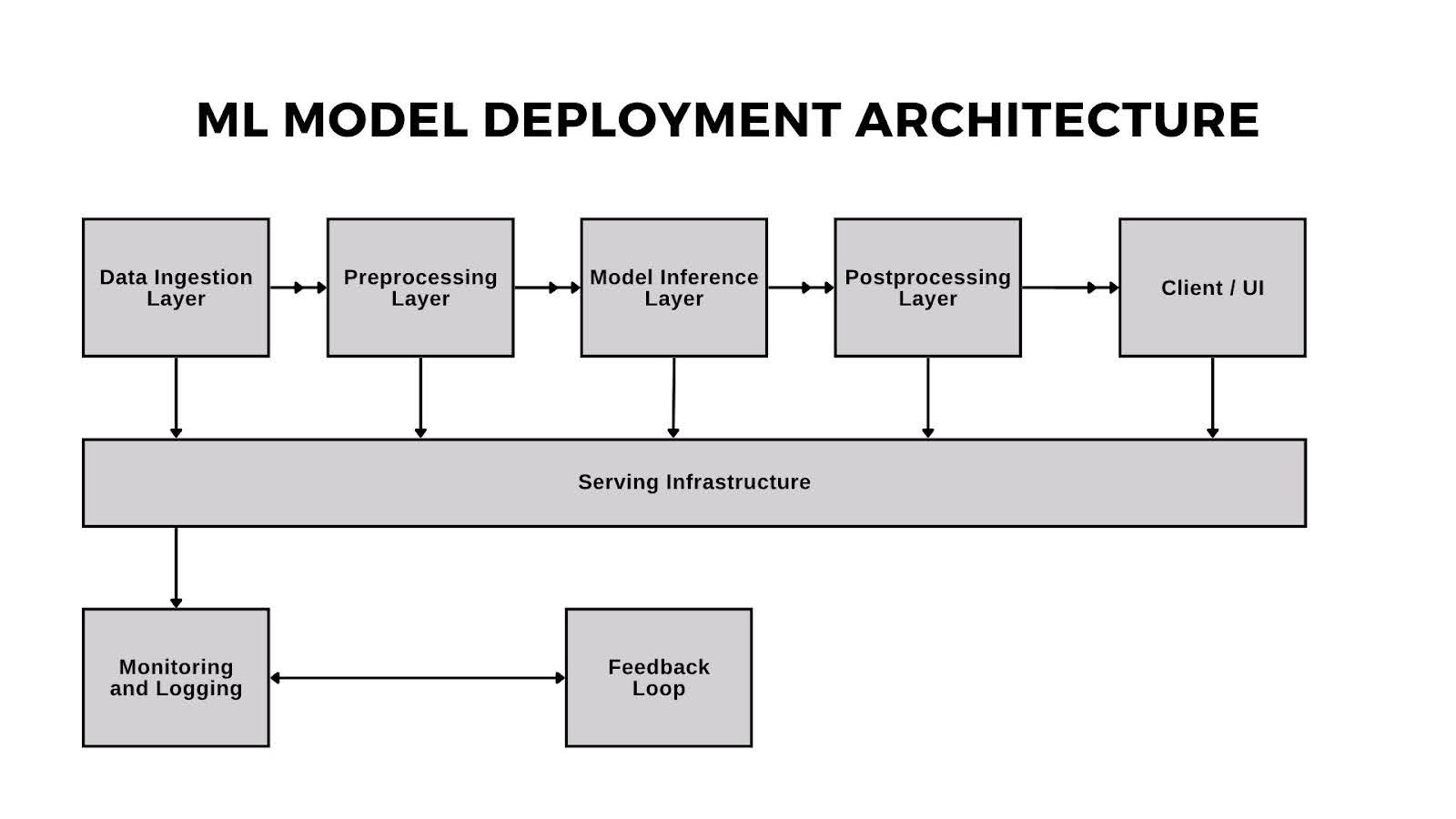
Data Ingestion Layer
Deployment architecture starts with a data ingestion layer: the entry point for raw input. Depending on the situation, this could be real-time data from RESTful APIs, data streams, batch files, or sensor input from IoT devices. The main goal here is that data flows smoothly and securely into the system for processing.
Preprocessing Layer
When data is collected, it usually requires preprocessing before it can go into the model. This can involve cleaning, normalization, encoding categorical variables, scaling numerical values, or applying domain-specific transformations. Preprocessing formats the new data in the same way as the training data, which is what the model is expecting.
Model Inference Layer
At the heart of the architecture is the AI model inference component, where the AI model receives the processed input and generates an output. Depending on the deployment strategy, inference can happen on-prem, in the cloud, or at the edge. The goal here is usually to deliver low-latency, high-availability predictions reliably and at scale.
Postprocessing Layer
Model outputs usually require further processing before they can be meaningful to users. Postprocessing can involve converting raw outputs into human-readable labels, applying thresholds to probabilities, or formatting results into structured responses. This step aligns ML outputs with business logic or user expectations.
Serving Infrastructure
Behind the scenes, the entire system runs on a layer of infrastructure that upholds reliability, scalability, and resilience. This layer is responsible for handling traffic spikes, deploying model updates, and ensuring uptime; serving infrastructure typically includes containerization, container orchestration, load balancers, and more. It’s also where Kubernetes management plays an important role for many organizations.
Monitoring and Logging
Observability becomes a priority once the model is live. The monitoring and logging layer collects metrics like latency, throughput, and error rates. Logging systems and metrics dashboards make it easier for teams to detect anomalies early, respond to issues, and maintain model performance.
Feedback Loop (Optional but Recommended)
An increasingly common addition to deployment architecture is a feedback loop. A feedback loop stores production data and user behavior for future retraining, evaluation, or experimentation. Feedback loops are foundational for mature MLOps workflows and long-term model health because they power continuous learning, support A/B testing, and increase business impact.
Model Deployment Best Practices
Deploying machine learning models successfully can be tricky, but best practices can help with stability, scalability, and maintainability. These eight best practices will help organizations deploy AI models confidently, maintaining performance over time and building trust with users and stakeholders.
1. Automate Everything
Automating the deployment process using CI/CD pipelines makes it easy for models to be tested and validated quickly. Additionally, automation reduces human error and makes deployments consistent and repeatable. Automated pipelines also speed up release cycles and provide a clear audit trail for changes in production.
2. Improve Model Containerization
Packaging models in containers is powerful because it allows the model to run reliably across different environments; containerized models can be deployed across cloud, on-premises, and edge environments without requiring platform-specific adjustments. Containerization also simplifies dependency management and makes it easier to deploy models at scale, specifically when using orchestration tools like Kubernetes.
3. Apply Version Control
Models and data should both be versioned to ensure traceability and reproducibility. By maintaining rigorous version control for code, artifacts, and training datasets, teams can roll back to previous versions if necessary and better understand how changes affect performance. Clear version histories also help data scientists, MLOps engineers, and other teams stay on the same page.
4. Integrate Rollback Mechanisms
Robust rollback mechanisms revert a model to a stable version if any issues are detected after deployment. Rollback strategies are especially important in high-stakes environments where model failures can have significant consequences. Automated rollbacks minimize downtime and user impact by quickly switching to a working version, reducing operational and reputational damage.
5. Enhance Model Tracking
Continuous monitoring of deployed models is critical to catch issues such as latency spikes, prediction errors, or data drift. Robust model monitoring will help catch issues before they balloon into bigger problems. Effective monitoring should track system-level metrics (latency, throughput, uptime) and model-specific metrics (accuracy, bias, drift) that can clue teams into proactive prevention.
6. Practice A/B Testing
Running controlled A/B tests allows teams to objectively compare the performance of different model versions in production. Testing provides valuable insights into how model updates affect key business metrics and user experience. Multivariate testing can even be used to test several versions at once, speeding up iteration cycles.
7. Adopt Security Hardening
Model APIs should be secured against threats such as unauthorized access, data leakage, or adversarial attacks. Security best practices include using authentication and authorization, implementing role-based access control (RBAC), and validating all incoming requests. Date should be encrypted in transit and at rest to safeguard sensitive user information, especially in regulated environments.
8. Normalize Consistent Compliance Checks
In regulated industries, model deployment processes should include checks for compliance with relevant laws and industry-specific standards such as GDPR or HIPAA. This may involve documenting model behavior, conducting fairness and bias audits, and maintaining audit trails. Routine checks also help make sure that models are not reinforcing discrimination or biases over time.
What Are the Top Model Deployment Challenges?
Deploying ML models brings unique challenges that go beyond those of traditional software engineering. Understanding the following obstacles is key to designing robust and maintainable deployment workflows that can stand up to real-world demands.
Data and Concept Drift
Over time, the data that models encounter in production may change; this is known as data drift. Similarly, the relationships between inputs and outputs can evolve, causing concept drift. Both forms of drift can degrade model performance and lead to inaccurate predictions. Without continuous monitoring and retraining, even a well-performing model can be rendered useless.
Monitoring Model Quality
Monitoring the quality of a deployed model is very important; unfortunately, it involves more intricacies than monitoring traditional software. Aside from checking for errors and uptime, models must also be monitored for shifts in prediction accuracy, fairness, and bias. This often requires advanced tooling and performance metrics that evolve alongside the model.
Dependency Management
Machine learning models rely on a complex stack of frameworks, libraries, and system dependencies. As new versions of ML libraries (such as TensorFlow or PyTorch) are released, teams have to manage versioning to uphold stability and reproducibility. Poor dependency management can cause production failures or inconsistencies between training and inference environments.
Latency Requirements
Real-time AI inference requires extremely low latency, especially in user-facing applications like recommendation engines or fraud detection. Achieving near-instantaneous response times requires careful optimization of the model and the serving infrastructure. Teams must also balance latency with other factors such as accuracy and complexity.
Resource Efficiency
ML models, especially large deep learning models, can become very compute-intensive. Keeping inference costs manageable relies on efficiently using resources such as CPUs, GPUs, and memory. Techniques like model quantization, pruning, and hardware acceleration can also help improve resource efficiency.
Cross-Functional Collaboration
Successful deployment requires close collaboration between data scientists, MLOps engineers, DevOps engineers, and product teams. These teams often have different methods, tools, and priorities, which can lead to friction if not carefully managed. It is important to build shared understanding, clear ownership, and strong communication practices for smooth deployments.
Recognizing and proactively planning for these setbacks will empower teams to build resilient and scalable model deployment pipelines. Addressing these challenges requires strong processes and collaborations, along with tools that unify deployment, inference, and monitoring into a streamlined workflow.
Mirantis k0rdent AI is designed to meet these needs by providing a platform for managing AI workflows with built-in observability, automated scaling, and Kubernetes-native orchestration. Mirantis k0rdent AI helps teams reduce the operational complexity of deploying and managing inference at scale, from initial deployment to monitoring and optimization.
Want to learn more? View the Mirantis AI Factory Reference Architecture.
Model Deployment Examples
Many industries are rapidly adopting ML models. Here are some practical examples where deployed models are already making their mark:
Recommendation Engines: Netflix, Spotify, and other streaming services deploy collaborative filtering models in order to make recommendations to users
Fraud Detection: Banks use real-time inference on transactions via scalable cloud endpoints
Computer Vision: Autonomous vehicles deploy models at the edge for low-latency object detection
Voice Assistants: Natural language processing models enable users to complete tasks like setting reminders or turning off devices with spoken commands
Healthcare: Models deployed in hospital systems assist with diagnosis or patient risk scoring
Machine Learning Model Deployment Tools
Listed below are some of the most popular AI model deployment tools and platforms:
| Tool | Use Case |
| AWS SageMaker | End-to-end deployment on AWS (deploy AI model on AWS). |
| Google Vertex AI | Full ML ops and deployment on Google Cloud. |
| Azure ML | Cloud deployment on Azure. |
| TensorFlow Serving | High-performance serving for TensorFlow models. |
| TorchServe | Serving PyTorch models. |
| ONNX Runtime | Cross-framework optimized inference. |
| KServe (Kubernetes + Knative) | Kubernetes-native model serving. |
| Kubeflow | Kubernetes-native ML pipelines and deployment. |
| MLflow | Open-source model tracking and deployment. |
| FastAPI + Docker | Lightweight REST API deployment. |
| Nvidia Triton Inference Server | High-performance multi-framework inference server. |
Selecting the right machine learning deployment method depends on factors like your application’s latency requirements, scalability goals, and existing infrastructure.
If you choose to containerize your models, you will also need a reliable platform for deploying containerized ML models, such as Mirantis Kubernetes Engine. You may also want to utilize a Kubernetes IDE such as Lens to simplify cluster management, resource configuration, and troubleshooting.
Many modern deployments also leverage AI Infrastructure as a Service or Inference as a Service offerings in order to abstract away infrastructure concerns. Platforms like Mirantis k0rdent AI offer a Kubernetes-native approach for managing and ensuring inference best practices, combining orchestration, monitoring, and performance optimization into a unified solution.
Simplify Machine Learning Model Deployment with Mirantis
Successfully deploying machine learning models involves more than writing good code: it also requires thoughtful planning, infrastructure readiness, robust automation, and ongoing monitoring to ensure long-term performance.
By following best practices such as containerization, CI/CD automation, and continuous monitoring, organizations can maximize the impact of their ML investments. With the right strategy and tooling, teams can move confidently from model development to real-world impact.
This is where Mirantis k0rdent AI comes into play. Built for Kubernetes-native environments, k0rdent AI streamlines model deployment and monitoring with the following benefits:
Centralized Management: Use a unified control plane to easily deploy, manage, and scaleinference endpoints across environments
Integrated Observability: Track model performance and resource utilization with built-in dashboards and alerts
AI/ML Optimized Infrastructure: Take advantage of ready-to-deploy service templates, a self-service model catalog, and intelligent routing of inference tasks
Want to streamline your model deployment? Book a demo today and see why Mirantis is one of the top solutions for enterprises.
)
)
)


)
)